
Introduction
Vous entendez de plus en plus souvent parler de Data Science, de recommandations basées sur des données de visite sur un site web ou des données d’achat sur un site e-commerce. De l’extérieur, cela ressemble un peu à de la magie : nous appelons l’oracle et il nous livre sa prédiction. Dans la pratique, ce n’est pas tout à fait cela, vous vous en doutez. Et c’est ce que nous allons voir dans ce post. L’objectif de ce post est de montrer (une partie de) la démarche du Data Scientist : quelles sont les phases structurantes d’un projet de Data Science ? Comment sélectionner un modèle ?
Si vous avez des données dans votre entreprise et que vous vous demandez comment elles pourraient être exploitées, ce post vous éclaircira sur la démarche du Data Scientist.
Je m’appuie sur un projet réalisé dans le cadre du Mooc de Udacity : Introduction With Machine Learning With TensorFlow.
J’ai présenté ce Mooc dans ce post là, n’hésitez pas à y jeter un coup si le sujet vous intéresse. Dans ce Mooc, chaque chapitre se termine par un projet. La particularité de ces projets et qu’ils sont complets et couvrent un large spectre de connaissances. Vous allez vous en rendre compte ici. Il faut compter une bonne dizaine d’heures pour terminer ce projet, entre la prise en main des données et la livraison du rapport.
Objectif
L’objectif de ce projet de Data Science est d’aider une association fictive de sélectionner des habitants à qui envoyer sa communication pour qu’ils fassent un don. Par souci de simplicité, nous considérons qu’une personne est susceptible de faire un don si elle gagne annuelement plus de 50.000$ .
Nous venons de réaliser la première étape (un peu trop facile ici) : déterminer la question à laquelle nous devons apporter une réponse. Sans question ou objectif business, la Data Science reste du confort.
Exploration
Comme tout projet de Data Science, la première étape consiste à prendre connaissance de cette fameuse data. L’objectif est de se familiariser avec pour mieux la manipuler et la faire parler après.
Les données à notre disposition nous viennent de UCI.
Les premières lignes de code indiquent le nombre d’enregistrements disponibles (45222) et un aperçu des premières valeurs.
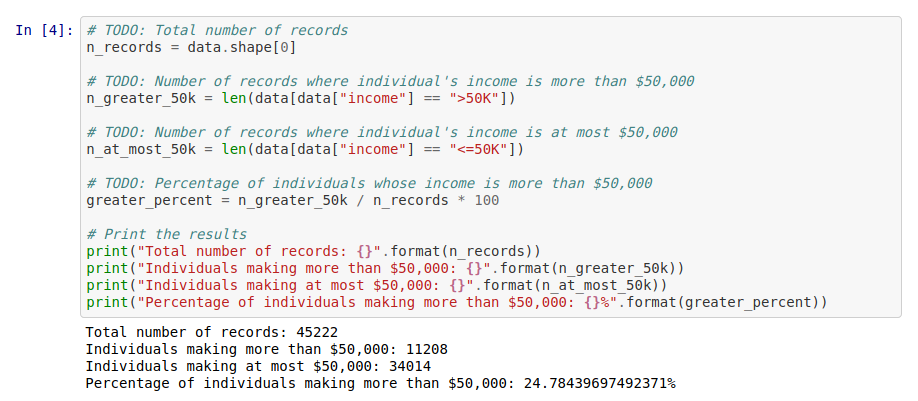
Nous vérifions la proportion des lignes répondant favorablement à l’objectif : 11.208 personnes gagnent plus de 50k (soit environ 25% des lignes).
Preprocessing
Avant d’envoyer les données dans un modèle, nous devons les préparer afin que ce dernier puisse travailler convenbalement. Cette étape s’appelle “Data Preprocessing”.
Cette étape est elle-même constituer de différentes sous-étapes en fonction de “la propreté” des données.
Valeurs manquantes
Dans la majorité des cas, il faut traiter les valeurs manquantes. Il existe une multitude de stratégie : inférence de valeur, suppression de lignes, suppression de colonnes… Tout dépend de leur proportion et du problème à résoudre (comme bien souvent en Data Science).
Heureusement pour nous, il n’y a pas de valeur manquante ici. C’est bien rare, mais pour une fois, nous n’allons pas nous plaindre, bien au contraire.
Données asymétriques
Par contre, notre jeu de données contient des données asymétriques (skewed en anglais). Des données asymétriques se caractérisent par le fait qu’elles sont éloignées et regroupées autour d’une valeur extrême. Certains algorithmes sont sensibles à cela et sont moins performants.
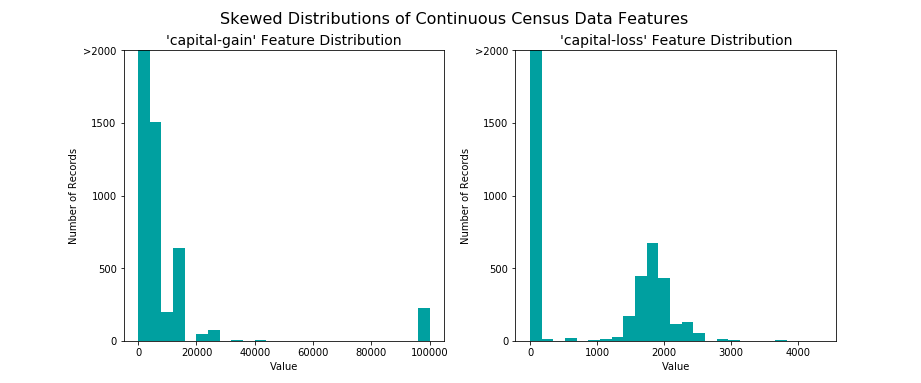
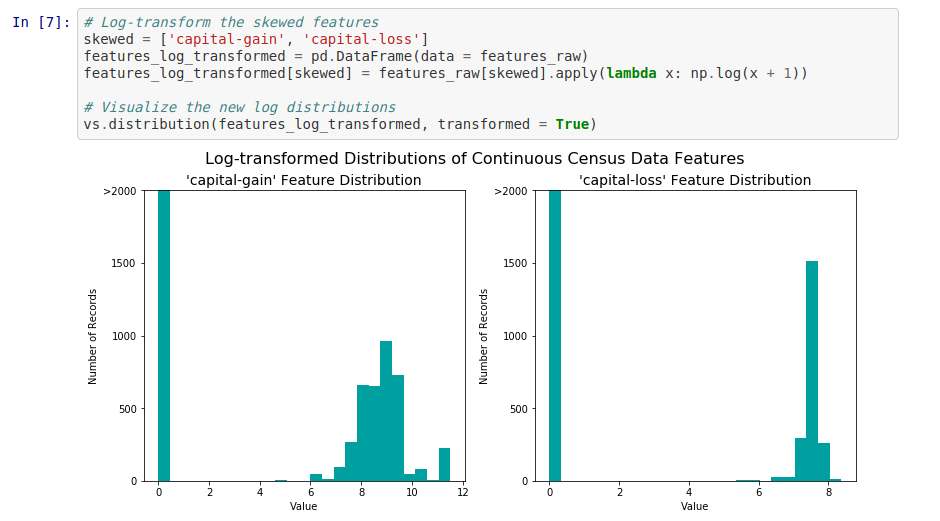
Une alternative classique et de transformer ces données en prenant le logarithme afin de lisser leur étalement leur “étalement”. Le logarithme n’étant défini que pour les nombres strictement positifs, nous translatons légèrement nos données pour respecter cette condition. Ici, nos deux colonnes “capital-gain” et “capital-loss” sont définies entre [0, +inf[. Une translation de +1 suffit largement pour ne pas avoir de valeur nulle.
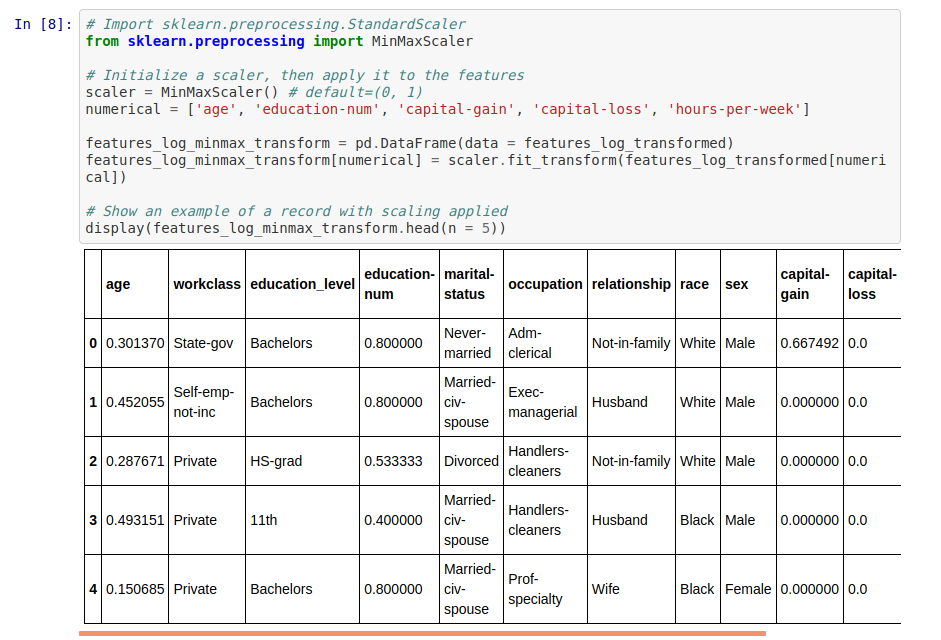
Normalisation des données
Afin d’éviter d’avoir des ordres de grandeur totalement différents entre nos différentes features (des ages compris entre 20 et 80, et des capital-loss compris entre 0 et 10) nous procédons à une phase de mise à l”échelle (Rescaling ou min-max normalization). Dans notre cas, nous effectuons à une mise à l’échelle entre 0 et 1. Ainsi, nous appliquons à une sorte de ré-étalonnement des valeurs afin que le minimum de chaque colonne soit 0, et le maximum soit 1. Bien évidemment, nous faisons cela uniquement sur les données continues.
One-Hot Encoding
Nous nous arrêtons là pour les données continues. Maintenant étudions les données catégorielles (categorical data). Typiquement, dans notre cas, la colonne income prends deux valeurs différentes : “≤50K” et “>50K”. Ce sont des chaînes de caractères et les algorithmes ne peuvent pas traiter cela. Nous allons donc transformer ces données spour les rendre exploitables.
Pour le cas précédent, nous remplaçons la valeur “≤50K” par 0 et “>50K” par 1.
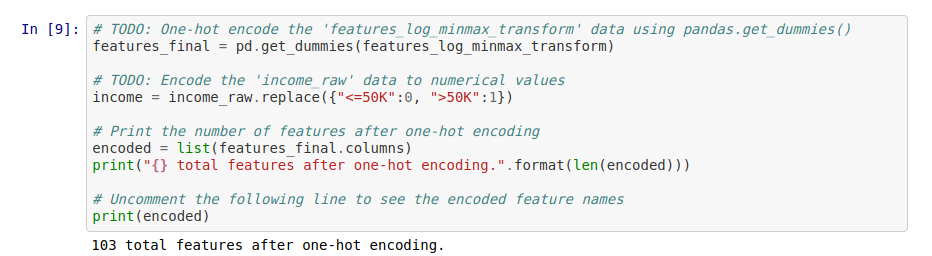
Pour les autres colonnes catégorielles, nous utilsons la fonction pandas.get_dummies pour effectuer du one-hot encoding (ou encodage 1 parmi n). L’idée derrière est de créer autant de nouvelles variables qu’il existe de valeur possibles et d’y attribuer 1 ou 0. Un exemple visuel est plus parlant :

Après cette étape, le nombre de colonnes a fortement augmenté. Nous en dénombrons maintenant 103.
Bilan du preprocessing
Nous avons normalisé nos données continues et nous avons converti nos données catégorielles en données numériques.
Nous allons maintenant séparer nos données en deux jeux : un jeu d’entraînement et un jeu de test. Généralement, la répartition est 80% / 20%. Pour rappel, nous entraînons notre modèle avec le jeu d’entraînement et nous mesurons ses performances sur des données qu’il n’a jamais vues : les données de test.
Mesure de la performance
Il existe un grand nombre d’indicateurs pour mesurer la performance. En fonction des problèmes, un indicateur est choisi plutôt qu’un autre. Je les détaille dans un autre post afin de ne pas alourdir celui-ci.
Dans notre étude, nous utilisons la justesse (accuracy en anglais, différent de la précision en statistique !). Cela représente simplement le nombre de cas correctement prédis par rapport au nombre total de cas.
Nous allons également utiliser le F-Score (plus précisément le F-Score avec un beta de 0.5). Je ne rentre pas non plus dans le détails. Pour faire simple, plus il est proche de 1, plus le modèle est bon (je reste volontairement flou sur “bon” pour ne pas rentrer dans d’autres considérations).
Maintenant que nous avons nos deux indicateurs, nous mettons en place un modèle de référence (baseline model en anglais). En général, nous le prenons le plus simple possible. L’objectif est ensuite de comprarer les performances de nos futurs modèles avec celles de ce modèle de référence. Nous cherchons à nous assurer que nous progressons dans la bonne direction.
Ici, nous disons que notre modèle de référence predit toujours 1, c’est à dire que la personne gagne plus de $50.000 à l’année (et nous allons donc la cibler pour notre campagne de communication). Avec ce modèle, les indicateurs ont les valeurs suivantes :
- Justesse : 24.8% (nous retrouvons bien la répartition explorée précedemment)
- F-Score: 58.4%
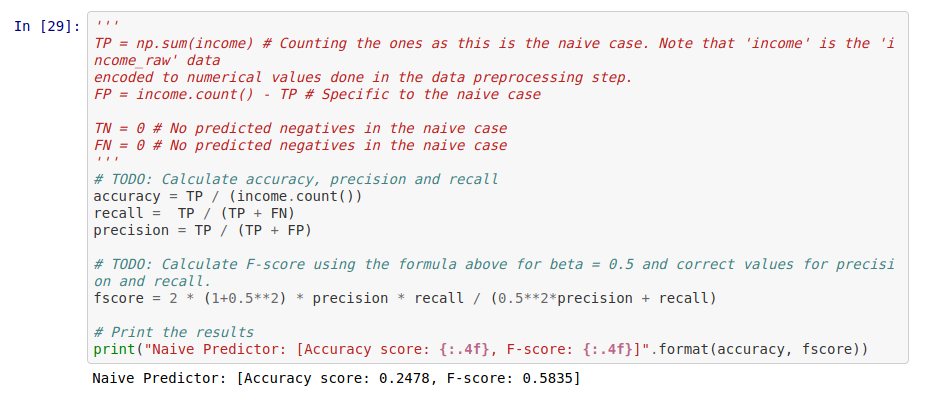
Autant être honnête, ce n’est pas phénoménal. En même temps, nous n’avons même pas pris le temps de lancer la moulinette. Au moins, nous avons maintenant une référence sur laquelle nous appuyer.
Le projet demande à ce moment d’étudier 7 modèles de machine learning et d’en sélectionner 3. Pour chacun des modèles, il fallait expliquer pourquoi il était pertinent pour notre problème. Malgré les apparences, c’est une partie super intéressante. Il faut farfouiller le web pour trouvers des artciles, des benchmarks… A travers cet exercice, nous consolidons nos connaissances et nous fixons mieux le fonctionnement de ces modèles qui nous ont été expliqué de manière assez haut-niveau pendant le Mooc.
Pour ma part, j’ai sélectionné les modèles suivants :
- AdaBoost Classifier
- RandomForest Classifier
- KNeighbors Classifier
La suite du code permet de comparer différents aspects :
- temps d’entraînement et de prédiction (sur le jeu de test)
- précision sur les jeux d’entraînement / de test
- F-score sur les jeux d’entraînement et de test
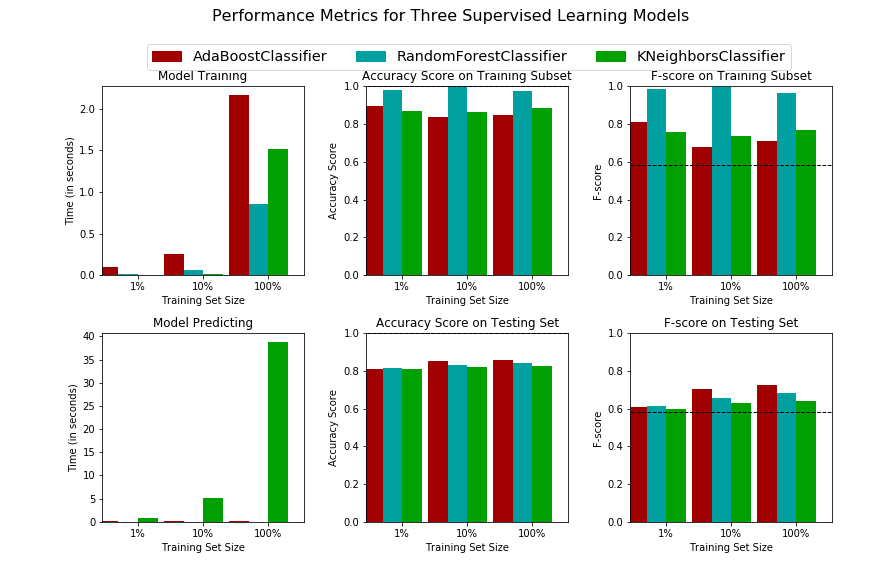
A partir ce ces résultats, nous sélectionnons un modèle afin de passer à l’étape finale.
Même si ses performances sont légèrement en deçà, j’ai choisi de garder le RandomForest pour les raisons suivantes :
- F-score et précision quasi-similaire
- Temps d’entraînement et de prédiction faible
- Facilité d’explicitabilité au client
En effet, la question suivante était d’expliquer le modèle choisi au client. Pour rappel, le client est une association de bienfaisance. Il faut faire preuve de pédagogie et user de nos plus belles métaphores.
Model Tuning
Nous rentrons maintenant dans la dernière phase : model Tuning. Autrement dit : aller à la chasse aux “pouièmes” pour augmenter les valeurs de nos indicateurs.
Pour cela, nous allons chercher la meilleure configuration du modèle pour notre modèle. Autrement dit, sélectionner précisémment ce que nous appelons les hyperparamètres. Chaque modèle a ses propres hyperparamètres.
Jusqu’à maintenant, nous avons gardé les valeurs par défaut.
Dans le cas d’une RandomForest, nous allons jouer sur le nombre d’arbres par forêt et la profondeur de chaque arbre.
En premier lieu, j’ai bien évidemment joué avec plus de paramètres. Mais le faible impact et le temps de calcul beaucoup plus long m’ont amené à ne considérer que ces deux paramètres.
Après avoir utiliser la fonction de grid search (recherche exhaustive qui teste toutes les valeurs données), nous obtenons la combinaisons d’hyperparamètres suivante :
- profondeur maximum : 16
- nombres d’arbres : 200
Mon correcteur m’a d’ailleurs indiqué que l’utilisation de RandomizedSearchCV (de scikit-learn) aurait pu donnée des résultats similaires en un temps plus court. Merci du conseil :
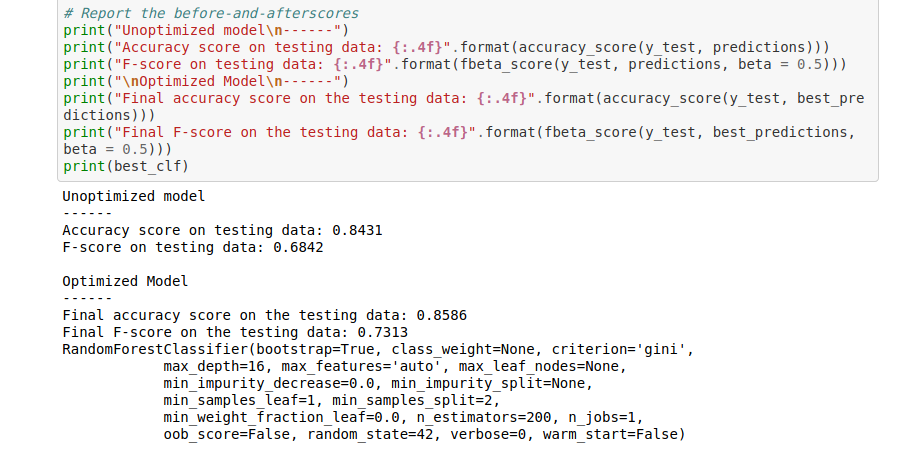
Grâce à cette optimisation, nous avons légèrement amélioré notre modèle. Nous avons gagné 2% de précision et 5% de F-score.
Nous n’en avons pas encore terminé. A vrai dire, un projet de Data Science n’est jamais vraiment terminé. Nous étudions maintenant les features importances.
Le but : sélectionner les features les plus pertinentes et éliminer celles qui n’apportent pas grand chose. En faisant cela nous réduisons la complexité du modèle. Les conséquences sont simples : un temps de traitement plus rapide et une explicitabilité accrue.
Dans le projet, il est demandé quelles features, apriori sont prédominantes dans le modèle. Cette étape oblige à être familier avec les données.
Ensuite, nous observons quelles sont les dites features qui ont le plus de poids dans le modèle. Dans notre cas, ce sont:
- les revenus annuels
- le statut d’être marié
- le nombre d’année d’études
- l’âge
- le fait d’être un mari (autrement dit être un homme et être marié)
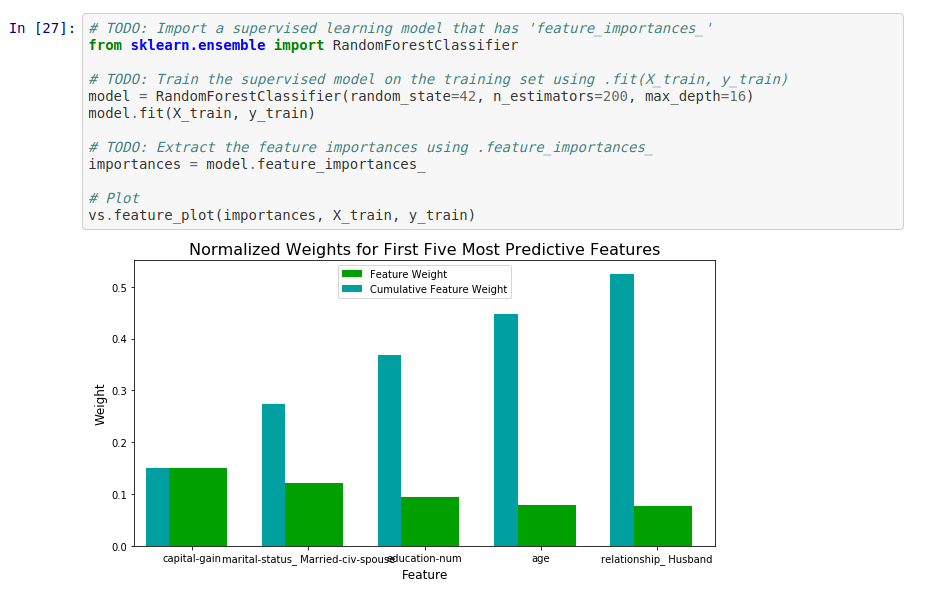
Avec un minimum de recul, nous pouvons très bien expliquer que tous ces éléments sont pertinents pour prédire qu’une personne gagne plus de 50.000$ par an.
Nous remarquons au passage que les données reflètent malheureusement les inégalités de la société. D’après ces 5 feautres, le modèle “privilégiera” un homme marié plutôt qu’une femme mariée.
Maintenant que nous avons ces features, nous allons recréer des jeux de données mais en ne conservant que ces features et voir quel impact cela a sur les performances de notre modèle.
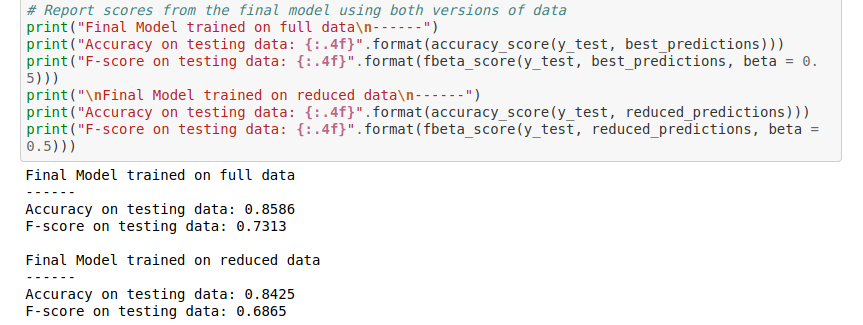
Dans notre cas, nous obtenons maintenant une précision de 84.25% et un F-score de 68.65%. La précision est quasiment identique que précedemment. Le F-score perd quant à lui environ 5 points.
En fonction des contraintes d’entraînement et de déploiement, il peut être plus pertinent de choisir un modèle beaucoup plus simple, mais qui sera plus rapide à donner ses prédictions. Dans notre cas, cela n’a pas vraiment d’importance. Dans un cas de recommendations e-commerce, ça se joue à 100ms près et nous aurions peut-être privilégier cette approche (après s’être penché sur ses performances d’entraînement et de prédiction évidemment).
Ce projet s’arrête là. Nous le soumettons ensuite et un correcteur le passe en revue. Comme je le disais dans le post présentant l’intégralité du mooc, les retours sont vraiment qualitatifs. C’est agréable et mine de rien, cela donne du crédit à votre travail. En voici un exemple.
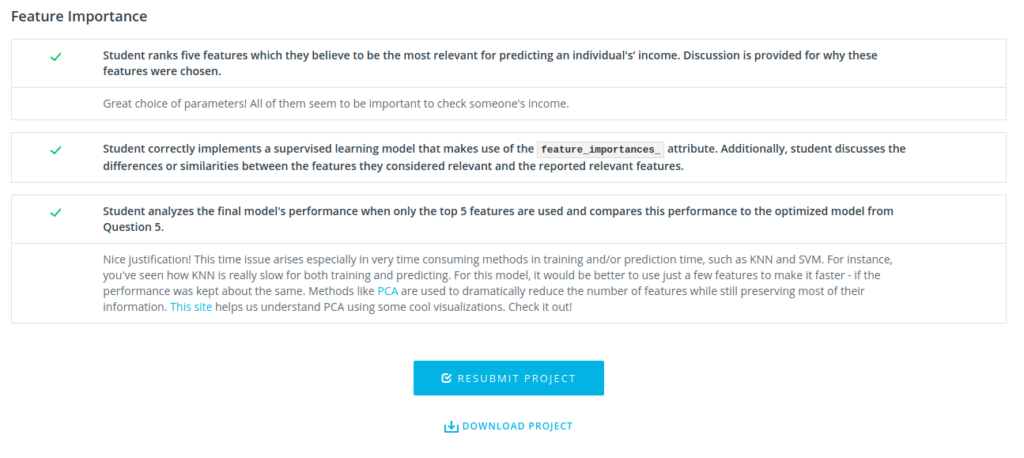
Dans un projet de Data Science, d’autres étapes peuvent venir s’ajouter. Par exemple, il n’a pas été question ici de feature-engineering, c’est à dire de la création de feature en combinant des colonnes existantes.
Il y aurait encore tellement à dire…
Conclusion
A travers ce projet du Mooc Udacity, nous avons pu mettre en application un cas de pipeline classique de projet de Data Science. Les grandes étapes abordées ont été :
- la définition d’un problème à résoudre
- le pré-traitement des données (Data Processing)
- le choix d’un critère de performance (Performance Indicator)
- la comparaison de différents modèles (Model Evaluation)
- l’optimisation du modèle le plus prometteur (Hyperparameters Tuning)
- l’analyse de ce modèle pour l’optimiser encore plus (Feature Selection)
Dans un projet grandeur nature, ces étapes se répètent encore et encore, afin d’aboutir au modèle le plus précis. Le cycle en V est impossible. C’est une affaire d’itérations, de tests, et d’exploration. Les avancées sont progressives. Parfois, il est possible de passer des heures à tester une hypothèse pour finalement se rendre compte qu’elle n’aboutit pas. Certes, le modèle n’est pas plus performant, mais notre compréhension du problème s’est affiné pendant ce processus.